

#124
A Case Study: Did AI speed us up - an honest take | How LLMs actually work | The real story with data centres --- and much more!
Welcome to another edition of our Builder Series Newsletter, where we dive into some of the challenges in building with AI, share research and wrap up all the latest AI news from across the world.
Did AI speed us up?
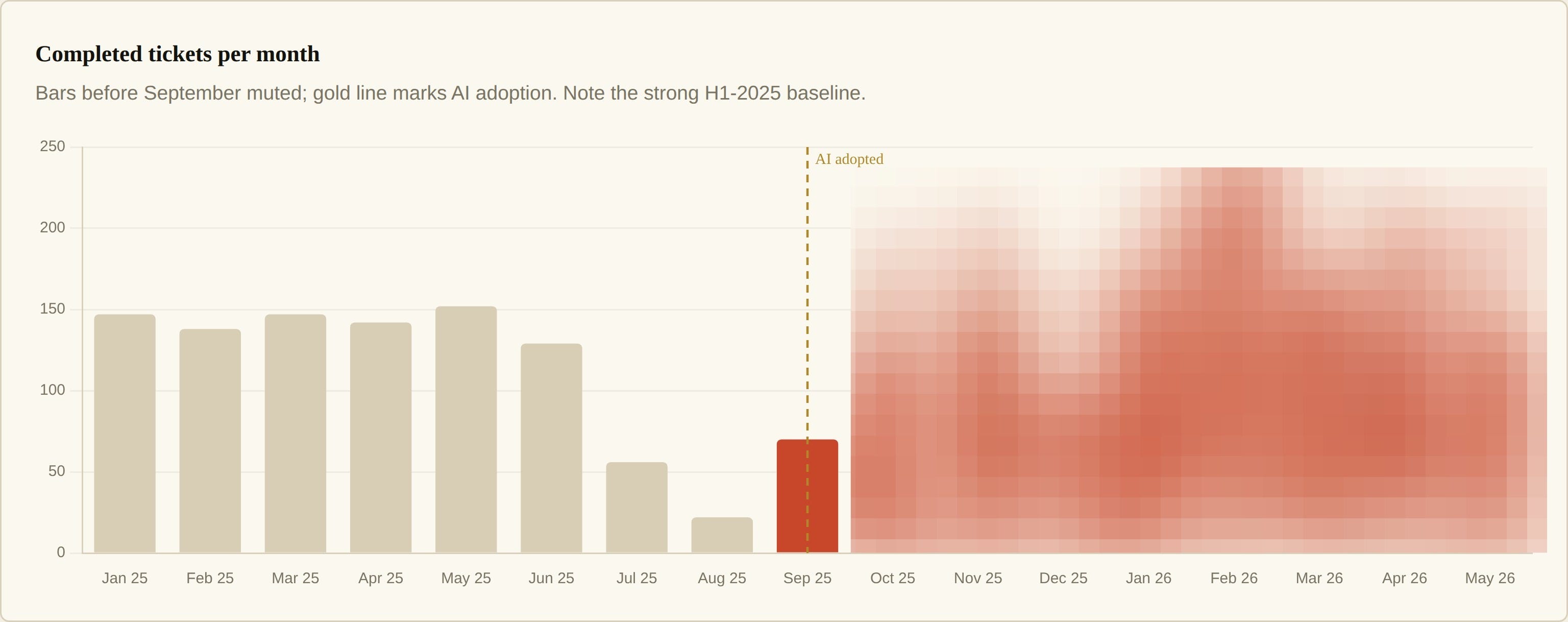
A trend analysis of 2,410 completed tickets at Kerno spanning January 2025 to May 2026, with focus on pre and post AI tooling adoption, September 2025.

Background
As the conversation about the return of investment (ROI) associated with AI intensifies I decide to do some analysis across our Linear database to see if AI has had an impact or not from an engineering velocity at Kerno. Notionally, being part of a small team you can ‘feel’ the productivity, but I wanted to anchor this in data.
My focus
If I asked each of my engineers the question… is AI helping you, the answer is an easy yes, but I wanted to look beyond the usage metrics. I wanted to understand the nuances and see if there were correlations across certain dimensions:
Adoption: While every team have AI power users, AI code generation can only have a true org wide uplift if the majority of your engineers are using it.
Bug Velocity: Shipping fast means nothing if what you ship is slop. While software bugs are part of doing business, I was interested in seeing if the bug velocity was up or down post introduction of AI.
Tokens: Another trend I was interested in, is how token consumption is trending. My assumption was we would have a sharp rise in tokens as we started using AI initially, but then it would fall somewhat and stabilise as we started using more skills, better scaffolding, memory layers and better prompting.
Summary
The analysis covers 17 months of completed Linear tickets, January 2025 to May 2026, split at the September 2025 adoption point: 2,410 tickets in total, 376 of them bug-labelled, against 17.25B AI tooling tokens (all sources, from August 2025).
At a glance:
+180% uplift in output per FTE
Ratio of bugs:output is no different between pre and post AI (adjusting for major refactor in March).
Token consumption starting to stabilise and decline.

Read the full piece with way more shiny graphs. Click on the image below

Read the full analysis here
Validate code in flow
Switching gears……
Meme of the week

News, views and more research
Borrowing Truth From the Future
Everything is built… just not in reality.

When we think of corporate fraud, the names come easily: Elizabeth Holmes at Theranos, Jeff Skilling at Enron, Sam Bankman-Fried at FTX. The one most people forget is Bernard Ebbers. As CEO of WorldCom, he oversaw an $11 billion accounting fraud, inflating reported profits by pressuring subordinates to cook the books. He was convicted in 2005 on securities fraud, conspiracy, and false filings, sentenced to 25 years, released in December 2019 on failing health, and died weeks later in February 2020. The collapse wiped out roughly $180 billion in shareholder value and gutted the retirement savings of people who never traded a share in their lives.
I bring up Ebbers because the WorldCom playbook (report the future as if it were the present, watch the stock climb) is structurally identical to a pattern emerging in the AI infrastructure buildout right now.
The mechanism: borrowing truth from the future
Compute is the currency of this era, and the market rewards capacity announcements almost reflexively. That creates an obvious incentive. If you tell shareholders you’ve brought gigawatts of data center capacity online when satellite imagery shows you paused construction months ago, and your stock rises on the news, you haven’t optimistically forecasted. You’ve manipulated the market. The legal term is securities fraud.
This isn’t hypothetical. Fermi, the Trump-branded Texas megaproject, had targeted roughly 1.1 gigawatts online by the end of 2026, then disclosed in an SEC filing that it no longer expects to hit that target; its CFO confirmed on the March earnings call that further construction is on hold pending a tenant and financing, and satellite images commissioned for a Cleanview report showed limited visible progress. In December, Bloomberg reported Oracle had pushed OpenAI-related completion dates out by a year on labor and material shortages. Oracle denied any delays to contractual milestones, but the stock had already dropped 3.6% on the report before paring losses. CoreWeave is now facing a securities class action (Masaitis v. CoreWeave, D.N.J.) alleging it overstated its ability to meet demand and understated infrastructure risk. The gap between what’s announced and what’s pouring concrete is where the legal exposure lives.
Why the buildout genuinely is hard
My background is civil engineering, and the part of that degree that sticks with me here is lead times, the time to source the critical materials a project depends on. A data center isn’t hard because the geometry is exotic or the terrain is difficult. It’s hard because it’s a logistics problem: millions of components, strict sequencing, and unforgiving deadlines, all of which carry a premium.
The supply picture backs this up. Bloomberg reported roughly half of US data center projects have been delayed or canceled on supply shortages and component dependencies; satellite analysis cited around AI construction suggests up to 40% of sites face delays; and the US is short something like 439,000 construction workers. SoftBank’s response, spinning out a company (Roze) to build data centers with autonomous robots and targeting a $100B IPO, tells you how acute the labor and timeline bottleneck has become. Add the grid: it can take up to five years for renewable projects to clear interconnection queues, and energy is now the binding constraint, not capital.
So to be clear about what I’m not saying: these data centers will get built. Nvidia, Meta, Microsoft, AWS all have the capex and the balance sheets. The issue is timeline. Completion on the schedules currently being forecast is not going to happen, and everyone close to construction knows it.
Why this matters beyond one stock
My problem starts when executives treat a forecast as a fact and let the market price it as one. Going public comes with a contract: ordinary, non-professional investors, your 401(k) and mine, get certain protections precisely because they can’t audit a construction site from satellite imagery. When the C-suite gets flippant with the difference between “contracted,” “under construction,” and “online,” that protection erodes, and so does trust.
The systemic stakes are larger than usual because the concentration is historic. As of late 2025, five companies made up about 30% of the S&P 500 and 20% of the MSCI World, the tightest concentration in roughly 50 years. JP Morgan’s Michael Cembalest has shown AI-linked stocks driving the bulk of market returns since ChatGPT launched. JP Morgan projects $5 trillion in AI infrastructure spending through 2030 against AI revenues that remain a fraction of that, what’s been called a “Grand Canyon-sized gap.” The financing is increasingly debt-driven: GPU-collateralized lending, record corporate bond issuance, private credit, and a meaningful slug of project finance whose repayment depends on data centers that may not get built on time. That risk doesn’t stay in tech; it reaches pensions, insurance, and bank deposits.
This is where I find it useful to zoom out. I’m fairly AI-pilled, but it’s worth listening to the other side, and Ed Zitron has been the loudest skeptic, arguing the spending commitments aren’t credible and that much of the sector’s revenue is circular (in 2024, of Microsoft’s ~$13B in AI revenue, ~$10B reportedly came from OpenAI’s own Azure spending). You don’t have to buy his conclusion that 2026 is the year it unwinds to take the underlying point seriously: a lot of market value is resting on commitments, not deliveries.
The takeaway
The buildout is real and most of it will eventually exist. But “eventually” and “this quarter” are not the same word, and the gap between them is exactly where WorldCom lived. What eventually really means is that this year we will see tokens costing more, and subsidises might end. Someone has the fund the debt gap, which is usually consumers.
The useful framework discipline is to separate three things every time you read an announcement: contracted capacity, capacity under active construction, and capacity actually online and drawing power. Companies blur those deliberately. The lead-time math doesn’t.
None of this is investment advice. I’m an engineer, not your financial advisor.
Open Weight Models — is the landing pad there?
H2 2025 was closed-weight’s time to shine — will H2 2026 belong to open-weight models? It was never really about whether the architecture is better, or even about the weights themselves. I see it more as a settling-in period: a lot of teams have grown comfortable working with LLMs and experimenting with open-weights, often locally. Just as AI-generated code had its gestation period, I think we’re now in the same kind of phase for getting used to open-weight models.
All I can say, is I am looking forward to the OpenRouter State of Play report 👀


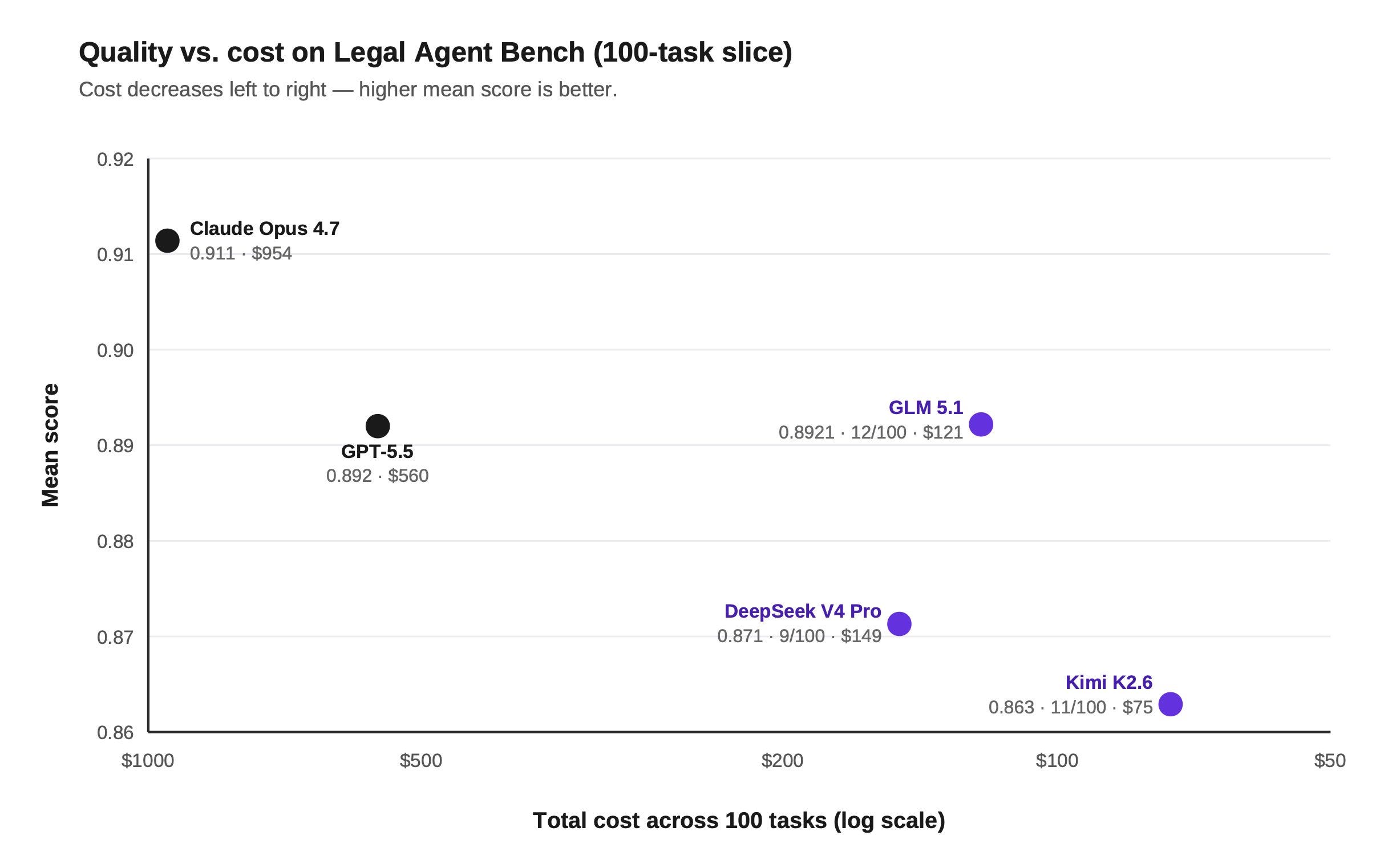
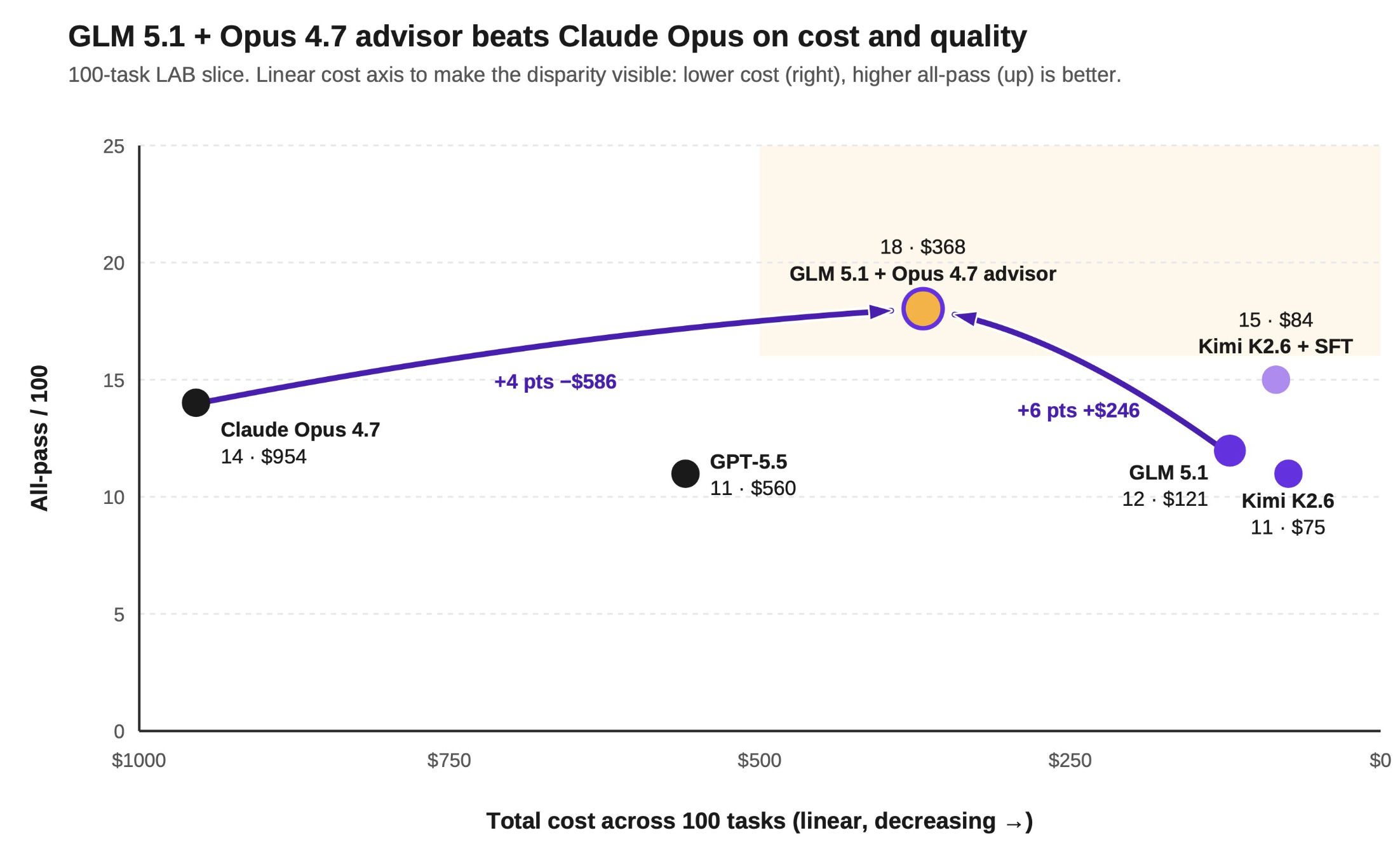
I guess the one obvious thing to point out, is that Harvey AI has a narrow focus, and can build experts into the open-weight models that represent more what they need, versus Anthropic/OpenAI who want to cover a broader range of topics. Everything from the encoding to the feed forward networking can be surgically altered by them to suit their needs - the real question is “is there enough engineers that have the required skillset”.
How LLMs actually work
BY 0xKato
Full article here.
One of the best pieces of technical writing I’ve come across. It weaves the core concepts behind LLMs into a single coherent picture, grounding each one in concrete examples, including why the real computation happens at the logit level.
The takeaway that stuck with me: the gap between Claude, GPT, Mistral et al is far narrower than people assume. Arguably, it’s marketing, not architecture or breakthroughs that’s generating most of the perceived value at these labs.
Fair warning: it’s long [26 min read], but goes deep on the following:
Embeddings
Positional Encoding
Attention
Multi Headed Attention
Feed-Forward Networking
Residual Streaming and Normalisation
Next Token Prediction
Architecture vs WeightsIt took me three to five passes before I gave up and turned it into a podcast-style piece, which finally gave me a solid intro. Once I’d heard that, I had enough of a foothold to read the main article without giving myself a headache. Want the md file? Restack or share the newsletter and I’ll send it straight to your inbox.
Agent traffic has overtaken human traffic on the internet

Cloudflare’s data has bots overtaking humans in web traffic for the first time, splitting HTTP requests 57.5% to 42.5%. CEO Matthew Prince had predicted this crossover for late 2027, then early 2027, and now finds himself watching it happen in mid-2026, a forecasting miss he conceded with a slightly pained “welp, that happened faster than I predicted.” Always reassuring when the person whose entire job is watching internet traffic gets blindsided by internet traffic.
The bots in question aren’t the old crawlers and fraud scripts everyone’s used to. These are agentic ones browsing on behalf of humans, reading product pages, comparing flights, ordering food, doing the kind of tedious clicking we apparently no longer wish to do ourselves. Prince did hedge that the exact crossover date is fuzzy because the data is “a bit messy,” but reckons we’re clearly past the threshold regardless.
Worth the asterisk Cloudflare itself adds: this measures HTTP requests, not engagement. Humans still dominate time-on-site, streaming, and doomscrolling, activities that don’t fire off page loads at machine speed. So humans aren’t outnumbered so much as out-clicked by things that don’t get tired.
👀👀 By country, the bot share peaks in Gibraltar (92.1%)???? wtf.. (gambling companies?), Singapore (76.4%), and Iran (76.4%), the latter likely a VPN-and-scraping-tool artifact rather than a nation of unusually busy agents.
Tooling Corner
Some free, open-source and paid tools (by startups) worth exploring.
📢 📢 📢 📢
Exclusive: Early access to Kerno Intelligence Tooling [KIT]
Give your AI agent a structured, deterministic map of your backend so it knows where to look and spends less tokens and context guessing.
Thanks for reading, For more AI Builder Series Editions, subscribe here.
AI Builders is sponsored by
